


Two example primitive visual concepts learned from annotation data.
Experiments with human subjects show concepts generalize and compose.
Why a Visual Concept Vocabulary?
Directions in a GAN's latent space can encode specific aspects of image semantics. StyleGAN trained on bedrooms, for example, contains a direction such that transforming most images along that direction causes indoor lighting to appear (Yang et al, 2019). However, current methods for identifying these directions are ad hoc, capturing only a limited set of human-salient dimensions of variation.
We present the first method to systematically catalog human-interpretable concepts in a generator's latent space.
How are visual concepts defined?
Our method is built from three components:
- Automatically identifying perceptually salient directions based on their layer selectivity.
- Collecting human annotations of these directions with free-form, natural language descriptions.
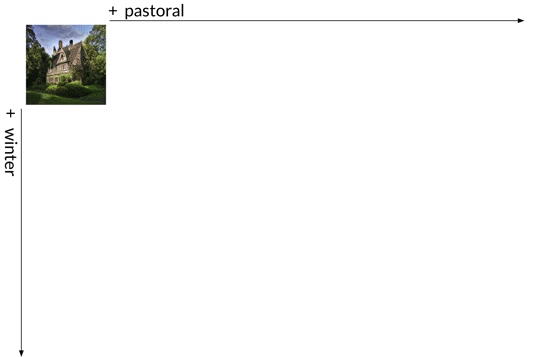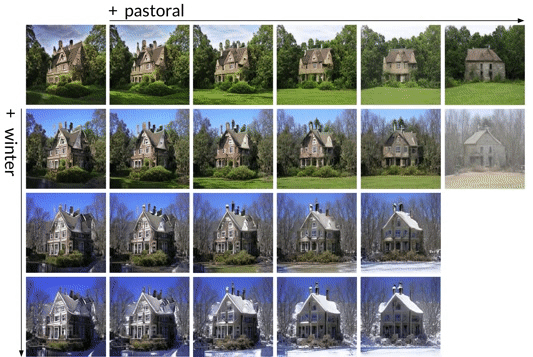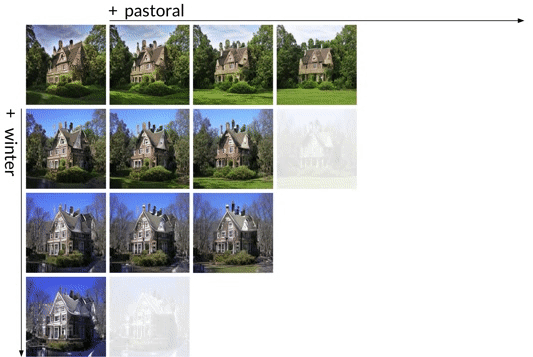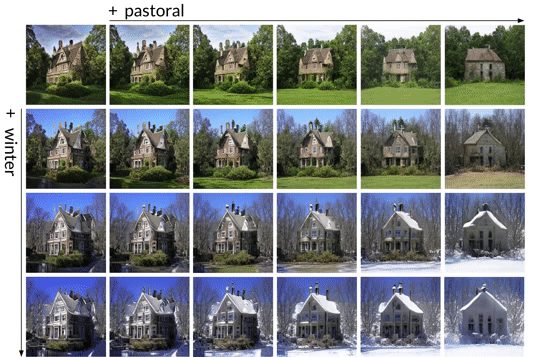
- Decomposing these annotations into a visual concept vocabulary consisting of primitive directions labeled with single words. Concepts can then be visualized by adding the corresponding direction to a latent vector, and running it through the generator.

Concepts can be subtracted as well as added. Subtracting the direction for winter yields a spring scene,
subtracting blue adds its complementary color, orange.
Our method uncovers diverse aspects of scene semantics, including higher-level experiential qualities of scenes. One direction makes a kitchen more welcoming by adding chairs and supplies, and another makes an outdoor market more festive by adding people and decorations.

+ welcoming

+ foggier

+ festive

+ spooky
The vocabulary is composable: directions can be combined to create novel concepts not present in the annotations. Additionally, concepts generalize outside of the image class in which they are learned. Below, spooky, learned in the cottage class, is used to create a spooky reflection on a lake.

+ arch + crowded

+ snow + clouds

+ spooky + reflection
We demonstrate our method on BigGAN (Brock et al, 2018) trained on Places365 and Imagenet. Directions and labels are available for download on our GitHub, and we will be releasing code for generating layer-selective directions and distilling a vocabulary of concepts for new models. The method is relatively model-agnostic, and can be used with any corpus of annotated directions. It enables:
- interaction with models using a shared vocabulary
- comparison of concepts represented by different generators
Get in touch if you try a similar implentation with another model.
Video
How to cite
Citation
Sarah Schwettmann, Evan Hernandez, David Bau, Samuel Klein, Jacob Andreas, Antonio Torralba. Toward a Visual Concept Vocabulary for GAN Latent Space, Proceedings of the International Conference on Computer Vision (ICCV), 2021.
Bibtex
@InProceedings{Schwettmann_2021_ICCV,
author = {Schwettmann, Sarah and Hernandez, Evan and Bau, David and Klein, Samuel and Andreas, Jacob and Torralba, Antonio},
title = {Toward a Visual Concept Vocabulary for GAN Latent Space},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {6804-6812}
}
Acknowledgments: We thank the MIT-IBM Watson AI Lab for support, and IBM for the donation of the Satori supercomputer that enabled training BigGAN on MIT Places. We also thank Luke Hewitt for valuable discussion and insight.